Compounding, charted

Most claims that a company is compounding are hand-waves. This essay is what compounding looks like when it's observable, falsifiable, and chart-able, what the substrate is, who it works for, and why it would survive being installed elsewhere on whatever AI tool you already use.
Heads-up on length: it's a long one, somewhere around forty-five minutes at average pace and less if you skim or are a fast reader. Section one is where the load-bearing claim lives, the rest is why that claim is defensible and what to do with it.
Second heads-up, because it's going to come up: this article was drafted by the AI co-author the article describes. Claude Code (Anthropic's agent, the same one I run inside the system) produced most of the prose against an outline I structured and the conventions already encoded in my corpus, and I edited, pushed back on framing, and kept what landed. The system uses AI as a tool, so the article using AI as a tool is the artifact demonstrating itself, and if that bothers you it's a real signal that the system probably isn't for your company, because installing this means using AI as a tool too. Bailing now saves you the read, reading on means you've understood the point.
1. What compounding actually looks like
Most founders telling you their company is compounding are hand-waving. They mean things feel like they're going faster than three months ago, the team has more momentum, the next launch is going to be easier than the last, all of which might be true and none of which is actually demonstrated anywhere. Compounding is what gets written into pitch decks under "Why now" and what nobody bothers to show you the data for.
Here's something I can describe specifically. Over the past month, I've moved seven different operational rules from "something I have to remember" to "something the system enforces automatically." The first three I did on the same afternoon as a batch. The fourth, fifth, sixth, and seventh came in the weeks that followed, each individually.
The threshold for what I'm calling "enforced" is mechanical. The rule went from being a habit or a piece of "be careful about this" to a pre-commit hook that refuses to commit code violating it, a content gate that refuses to send an email containing a fabricated claim, a schema validator that refuses to write a config file with a typo'd vendor name. Each one is a moment when prose became code.
The thing worth noticing isn't the count, it's how much easier the later ones were than the earlier ones. The first enforcement I built took most of a working week. It required figuring out what "fail-closed" should mean, where in the pipeline the gate should sit, what the bypass syntax should be when the gate misfires, how to write a test that proves the gate fires when it should and doesn't fire when it shouldn't. By the time I got to the seventh, the substrate that the new gate plugged into already existed. I did the substrate work in an afternoon and the new enforcement was live before dinner.
That's compounding, not the metaphor but the actual phenomenon, and the thing nobody talks about is it doesn't usually look like anything from the outside. The first rule and the seventh rule each look like the same thing, a markdown file plus a pre-commit hook. The compounding is invisible until you map the time each one took. I have that map internally, I'm not publishing the cadence as a chart because doing so turns the cadence itself into a target, and that's a specific Goodhart failure mode I'd rather avoid (section 10 has the longer version).
A caveat before we go further. This is one month of work, on seven enforcement moments. Four weeks of substrate-reuse acceleration is consistent with compounding, and it's also consistent with a learning curve on a new toolchain, with low-hanging fruit getting picked first, or with a productive stretch that hasn't ended yet. The internal cadence data doesn't tell you which on its own. I'm calling it compounding because the structural reasons for the acceleration, substrate reuse, rule-citation densification, AI co-author retention, are visible in the artifacts and not just in the time-per-enforcement curve. The claim earns its weight by surviving more time. Section 10 lays out the falsification cases for this and several other claims explicitly.
This essay is about what compounding looks like when it's specific rather than rhetorical, what it took to build, and whether you can install one in your own company.
A heads-up about what this is and isn't. It isn't a pitch for the underlying business. The business is Municipal Alpha, a data product that converts municipal records into investable signals for capital markets and infrastructure investors, and that's not what we're going to talk about here. The business is the proving ground. What we're going to talk about is what's underneath: the operational substrate that makes the compounding possible.
Call it a compounding system, call it a founder OS, call it whatever you want, the substance is what it does, not what we name it.
Some sections will be technical. I'll keep the jargon honest. If you've ever maintained a software project with more than one contributor, the file-system patterns will feel familiar. If you haven't, the prose will tell you what you need to know.
The structure of the rest of this piece:
- What the underlying corpus is. (How many records, how it's structured, what's queryable.)
- How rules emerge from the corpus. (The lifecycle from "habit" to "principle" to "commandment.")
- What "enforcement" means in practice. (The substrate that makes a rule load-bearing instead of advisory.)
- How an AI co-author fits into the loop. (The unusual part, and the part that's hardest to copy.)
- What meta-mining is, with a worked example from one Friday night. (The corpus is queryable for patterns the founder didn't know to look for.)
- The portable core, six pieces. (What you'd actually need to install one of these elsewhere.)
- Why this raises the company's enterprise value, not just its operational velocity. (What an acquirer is actually buying, hypothesis, not validated case.)
- What it doesn't do. (Honest limits on who the system is for.)
- The honest case against the article itself. (Where the framing overreaches and where the evidence is thinnest.)
Then a small note on what comes next, for me and possibly for you.
2. The corpus is the asset
If you're going to build a system that compounds, the first thing you need is a substrate to compound on. In my company that substrate is a decision corpus, which is not the same thing as a journal.
A journal is a record of what you did. The reader is your future self, and the format is whatever you felt like writing that day. The cost of writing a journal is low and the value is bounded by how often you go back and read it, which in most companies turns out to be approximately never.
A decision corpus is a structured, tagged, queryable record of what was decided, when, by whom, in what session, and pointing to where the full reasoning lives. The reader is not just your future self; the reader is also the AI co-author that loads the recent slice of the corpus at the start of every session, and the meta-mining script that runs against the whole thing once a month to find patterns. The format is not whatever you felt like writing that day; the format is enforced.
Mine looks like this. Every working day gets one markdown file at docs/decisions/YYYY-MM-DD.md. Inside that file, each session is a top-level heading. Inside each session, each discrete decision is a tagged subheading: ### [DECISION] Tier line sharpened, ### [BUILD] Three charts for the long-form article, ### [FIX] gmail_client._detect_hard_wrap extended. There are about ten tags in active use. They emerged from doing the work, not from a meeting where someone designed the taxonomy.
A small script reads every daily file once a day, extracts the tagged headings, and rebuilds two derived files. One is a JSON Lines file, one record per decision, schema fixed at version 3.1 and validated on every rebuild. The other is a markdown index that lists every decision in reverse chronological order with anchor links to the full prose. The JSON Lines file is what programs query. The markdown is what humans grep.
The corpus is currently 1,169 records across 68 daily files, accumulated over 46 calendar days. The records distribute across tags as follows: DECISION 380, CAPTURED 274, FIX 147, BUILD 107, DEFERRED 63, SEND 40, DIAGNOSED 35, INCIDENT 28, RULE 19, plus a long tail of less-frequent tags. The volume curve over time tells its own story:
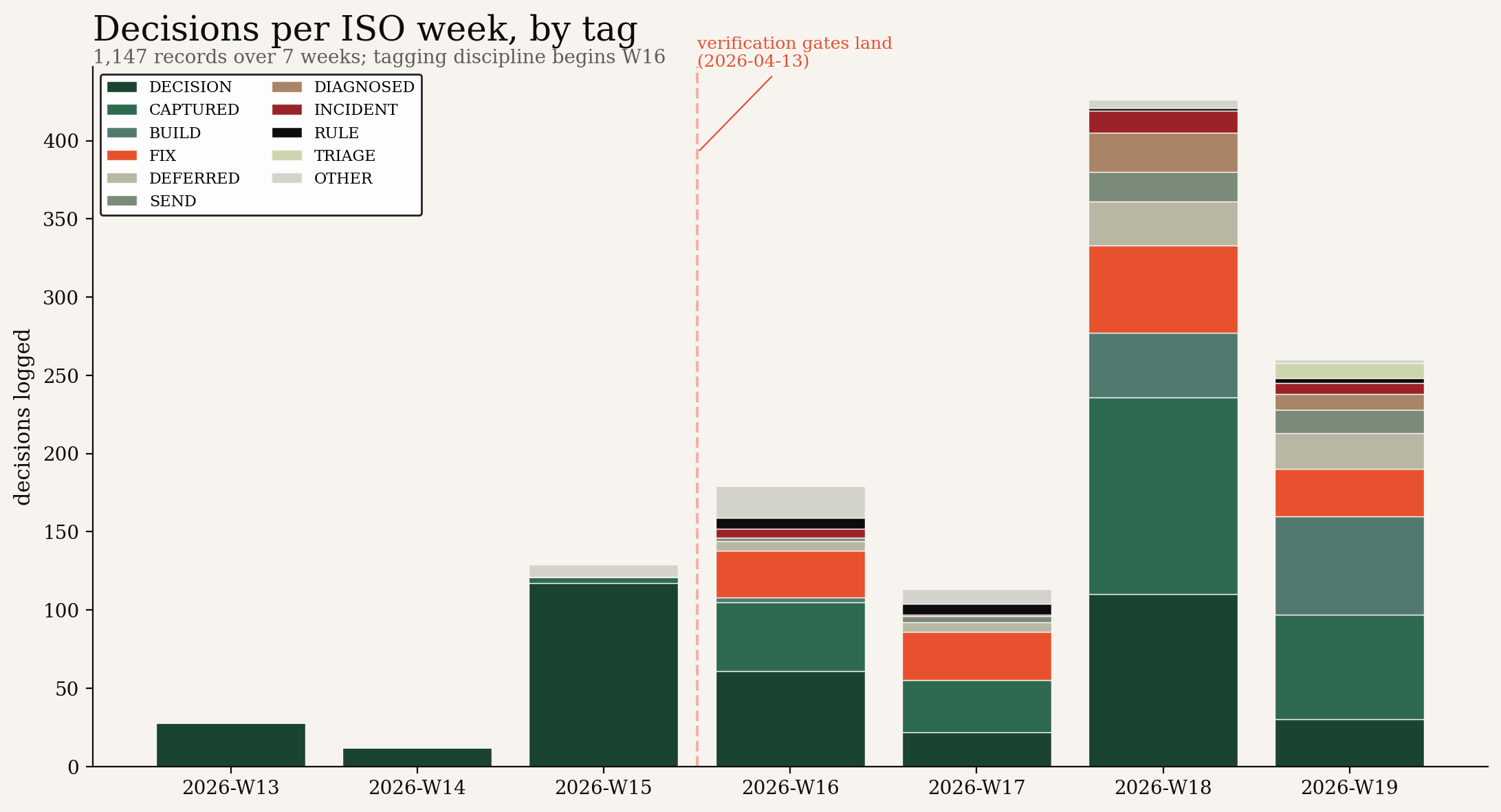
Three things in that chart worth noticing. First, the early weeks have a single tag. Everything was just DECISION, because that was the only tag the system knew. Second, around week 16, the tag spectrum opens up. CAPTURED, BUILD, FIX, INCIDENT, RULE, DEFERRED all start appearing in volume. That isn't because the work changed; the work was already differentiated. The tags caught up to the work. Third, the volume itself climbs from twenty-eight in week thirteen to four hundred and twenty-six in week eighteen, a fifteen-fold increase in six weeks. The corpus didn't get more verbose; it got finer-grained.
The taxonomy emerged from use, and that matters for two reasons. The first is practical, a pre-designed taxonomy is theater, you sit in a meeting, agree on a set of categories that sound right, and never use them, because the actual work doesn't fit the categories you imagined. An emergent taxonomy fits because it grew out of doing the work. The second reason is structural. Every time the system noticed itself doing something it hadn't named yet, it produced a new tag, and from then on that class of work is queryable. The corpus learned that there's a difference between a [BUILD] (something new exists) and a [FIX] (something broken now works) and a [DIAGNOSED] (the cause of something has been understood, but no fix exists yet). Those are real distinctions. They turn out to matter when you mine the corpus.
This is the asset, not the data product the company sells, not the code that runs the pipeline, but the corpus and the system that maintains it.
The Echo Nest analogy is the right structural shape to lean on here, used carefully. Echo Nest's audio-fingerprinting platform was the asset Spotify acquired, by way of analogy, not employment history, in 2014; the consumer-facing music recommendation apps were the proving ground that demonstrated the platform worked. TechCrunch's coverage framed it bluntly: in this analogy, Spotify gained control of the music-intelligence company that was powering its rivals, Rdio, iHeartRadio, Deezer, Rhapsody. The platform traveled because it was structured to travel. The shape transfers: the vertical that proves the system out is Municipal Alpha; the system itself is what lives portably underneath. The historical specifics (audio APIs, data corpus, licensing relationships) don't transfer, and shouldn't be asked to.
3. How rules emerge
The corpus is the substrate. Rules are what grow on top of it.
A rule, in this system, is a piece of guidance that's been extracted from observation, written down in a named file, and loaded into the AI co-author's context whenever it's relevant. It isn't a wish, it isn't a "best practice" anyone wrote on a Notion page, it's something specific enough that you could check whether it was being followed.
Rules emerge through a four-stage lifecycle, and each stage has a promotion criterion that's specific rather than vibes-based.
The first stage is practice. A practice is a thing you've noticed yourself doing the same way three or four times. It might be how you handle a particular kind of email reply, or the way you frame a follow-up to a buyer, or a habit of running a check before a particular kind of commit. At this stage the practice lives entirely in your head, unnamed and uncaptured.
The second stage is rule. A practice becomes a rule the moment you write it down in a file with a name, a description, and a "when to apply." The rule lives in the rules directory. It gets loaded into the AI's context whenever its trigger condition fires (for example, when you're working in the relevant module). The rule is now reproducible across sessions. You can forget it; the system won't.
The third stage is principle. A principle is a rule that subsumes multiple specific rules under one higher-level idea. The promotion criterion is concrete: when at least three rules can be expressed as instances of a more general statement, you stop maintaining the three rules and you maintain the principle. Three rules about "don't fabricate dollar amounts," "don't fabricate vote counts," "don't fabricate quoted phrases" become one principle: every claim traces to a source. The principle covers cases the original three rules didn't anticipate.
The fourth stage is commandment. A principle becomes a commandment when an independent failure mode shows the principle was load-bearing all along: violating it produced consequences the system couldn't recover from gracefully. A commandment is irreducible. It can't be expressed as a more specific rule, because it's already the most general statement about a class of failure. There are currently twelve commandments. They are not aspirational; they are the things that, when violated, the system measurably and detectably gets worse.
The promotion criteria matter because they keep the rule layer from becoming theater. Without explicit criteria, every interesting observation gets enshrined as a rule, and the rules directory grows into a wishlist nobody reads. With explicit criteria, rules earn their place by demonstrating that they're load-bearing: a rule that's never cited, never subsumed, never enforced is a candidate for deletion, not a candidate for promotion.
The compounding shows up in the citation graph between rules.
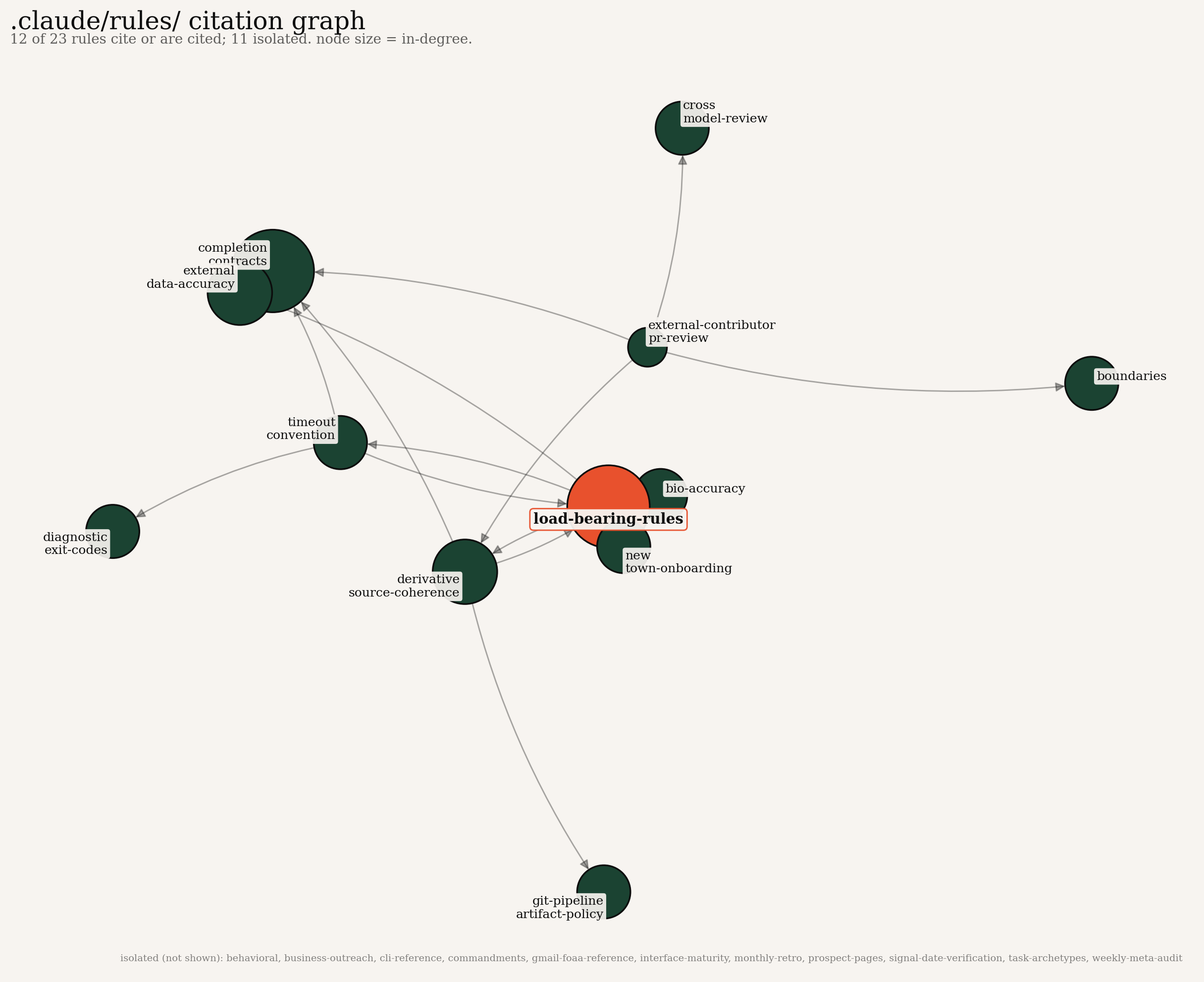
Each node is a rule file. Each edge is a citation: rule A's text references rule B. Newer rules cite older ones. The graph has a clear keystone, the central orange node, which is the file that tracks which advisory rules got promoted to enforcement. Every recently-built rule cites it, because every rule's path to mattering runs through it.
This isn't metaphor, this is compounding visible in the literal file-reference structure, and the graph densifies over time as new rules plug into the substrate that older rules built. A new rule can be twenty lines because it can lean on the four rules it cites. The first rule in the graph couldn't be twenty lines, because there was nothing yet to lean on.
A worked example. On April 14 of this year, my VPS pulled a git pull that failed because a derivative file (a generated index of decision logs) had been committed in a state inconsistent with its source. The reason was specific and instructive: a session ended, the source was edited, the derivative was rebuilt against the in-memory edits, the derivative was committed, the source was not. On a fresh clone the derivative looked stale because the rebuild against committed-source produced a different output. The rule that came out of this incident, "never commit a derivative whose source has unstaged modifications," was written to the rules directory advisory-only. It sat there for twenty-two days. Then, on May 6, a pre-commit hook went in that enforces the rule mechanically: refuse the commit if any staged derivative has an unstaged source. The rule didn't change. The text is the same. What changed is that the text became code.
That twenty-two-day gap, between writing the rule and making it load-bearing, is the gap the next section is about.
4. The enforcement substrate
The single most important idea in this whole system is also the simplest: a rule the system can't catch is a reminder, not a rule.
Here is the test that decides which is which. For any rule, ask: if this rule were violated right now, would any tool catch it? If yes and the tool fails closed (refuses to commit, refuses to send, refuses to render), the rule is load-bearing. If yes but the tool only warns or logs, the rule is partially load-bearing. If no, the rule is advisory.
Advisory rules decay, the text persists but the force doesn't, people forget, new tools skip them, context shifts and the rule keeps existing in the rules file while losing its force in the operation. That isn't pessimism, it's the empirically observed half-life of any guidance that depends on a human remembering it under pressure. The rule that prevents you from sending an email containing a fabricated claim isn't the rule, the check that refuses to send the email is the rule.
The enforcement substrate is the set of mechanical gates that turn rules into checks. In my system it currently includes:
- Pre-commit hooks that refuse a commit if it stages a derivative artifact whose source has unstaged modifications, if it stages a deploy script with an un-timeouted Python invocation, if it changes a municipality YAML that fails schema validation.
- Pre-push hooks that run a code-health gate on changed files and block on critical or high security findings.
- Content gates wired into every external-content generator. Before a draft alerts email is rendered, a verification pass extracts every numeric claim, every quoted phrase, every named entity, and refuses to render if any of them can't be traced to a source in the underlying database.
- Schema validators that refuse to write a config file with a typo'd vendor name, a missing required field, or a value outside the allowed enumeration.
- Drift detectors that read prose claims (the open-items file, the time-tracking summary, the derived ledger) and flag inconsistencies against the database that prose is supposedly summarizing.
- Freshness checks that refuse to treat a derivative artifact as current if it was built against a source-state that's not in HEAD.
There's a literal file in the rules directory called load-bearing-rules.md. It contains a markdown table that tracks which rules have been promoted to enforcement, when, by what mechanism, and what triggered the promotion. Each row is a moment when an advisory rule earned its tooling. Right now there are seven rows.
The seven rows are why I keep calling this compounding rather than just productivity. Each new enforcement reuses substrate from the previous. The first promotion required building a verification module from scratch: how to extract claims from prose, how to canonicalize them for lookup, how to fail closed without breaking the developer flow. The second and third promotions plugged into that same module. The fourth promotion required different substrate (a content scanner for external markdown files); the fifth, sixth, and seventh plugged into that. By the time you get to the seventh, the marginal cost of "wire this rule into the substrate" is a couple of hours.
This is one specific kind of compounding worth distinguishing from the others the article points at. The substrate-reuse pattern is substrate reuse: each gate makes the next gate cheaper to wire. That's a learning-curve dynamic with structural reasons behind it. It's distinct from corpus accumulation (linear growth in the volume of decisions retained, not exponential), and distinct again from rule-citation densification (network-effect-style interconnection growth in the rule layer over time). All three feed each other in practice, but they're different phenomena. Lumping them under one word makes the system sound more unified than it is. Substrate-reuse is a learning curve, corpus accumulation is linear, only the third has the network-effect property that "compounding" usually implies in its strongest sense.
The cadence chart is the most concrete claim of compounding I know how to make. Most operating systems don't have this chart, because most don't have a load-bearing-rules table, because most rule layers don't distinguish between advisory and enforcement, and that distinction is the substance. If you can't say which of your rules are enforced and which are reminders, you're working in a system whose half-life you can't measure.
There is a candidate thirteenth commandment waiting for promotion, sitting at the bottom of the load-bearing-rules file. It says: enforcement is the substance of a rule; the text is the specification of the enforcement. It will be promoted on the next instance of an advisory rule failing for lack of enforcement, because that's how every commandment in this system has earned its place: an independent failure showed the principle was load-bearing all along.
5. The AI co-author
This is the part of the system that's the hardest to copy and the most worth copying. It's also the part that requires the most care to describe honestly, because it's easy to overclaim and the article gets worse if I do.
Most founder operating systems are paper, the decision log lives in Notion or a Google Doc, the rules live in a wiki, the conventions live in someone's head, and none of those formats are queryable by anything other than a human, who only queries them when they remember to. The corpus exists but it's inert.
The system I'm describing has an AI co-author inside it. The reference implementation in my setup is Anthropic's Claude Code, running in my terminal, but the pattern would work with comparable AI agents, and I'll come back to that question explicitly at the end of this section, because it's the question I'd ask if I were reading this from somebody else's machine. For now, the specifics that follow describe Claude Code, because that's the system I actually run.
At the start of every session, before I type anything, the AI co-author loads about thirty kilobytes of operational context: the bootloader file (Claude Code calls it CLAUDE.md), the always-loaded rules, the most recent decision logs, the user-level auto-memory file (a ~280-line index of every behavioral preference, project memory, and reference pointer it has on me), the open items list, and any conditional surfaces firing that day (a pending retro draft, a meta-audit with non-zero findings, a morning briefing JSON if one was generated overnight). Then it runs a nine-step session-start protocol. The protocol is mechanical: check git state, fetch any commits the remote has that local doesn't, look for parallel-session work in the working tree, check the rat-hole guard against the open-items file, check whether it's the first session of the ISO week (which triggers a competitive-intel scan and a weekly Gemini review), check whether it's the first session of the month (which triggers a retro), look for an overnight briefing.
Only after that does it ask me what I want to work on.
The protocol exists because context resets are expensive. Every time I start a new session, I'm spending compute and money to bring the AI back up to where it was at the end of the last session. The protocol minimizes that cost by automating it. By the time I describe what I want to do, the co-author already knows what was done yesterday, what's in flight, what's blocked, what should be on my mind, and which of its own enforcement gates are armed.
The volume of decision-log prose authored by the co-author versus authored by me is roughly sixty-forty in favor of the co-author at the moment, but I have to be honest about what that number does and doesn't mean. It looks like an altitude shift, where the founder's judgment is being progressively extracted and the AI is doing more of the cognitive work, but it isn't, and the shift is mostly explained by a change in how sessions are named, which happened on April twenty-fourth. Before that date, every session defaulted to my name as author; after, sessions where the AI does the writing are tagged accordingly. The author tag tracks who-wrote-the-prose, not who-made-the-judgment. I caught this mining the corpus a few hours before this paragraph was written, and it was useful as a methodology lesson: attribution metrics that change meaning when conventions change are not safe to read as trend signals.
So what's the actual division of work?
My honest read of the corpus, having mined it specifically to answer this question: the system handles about thirty to forty percent of the cognitive load autonomously. That's the session-start protocol, the pre-commit and pre-push enforcement, the drift detectors, the freshness checks, the conditional retros and audits, and the AI co-author rendering my decisions into prose that obeys the established conventions. I do the other sixty to seventy percent: the substantive judgment about what to build, what to ship, which rules to promote, which trade-offs to accept, what the next thing is.
That's not a small contribution from the system. But it's not "AI does the work for me," either. The honest framing is this:
The system retains everything I do and compounds on it. I still do most of the substantive work; I just don't redo it.
The next session starts where the last session ended, with a structured representation of what I decided last session loaded into context, and the rules I've previously found to matter active. That continuity is the structural difference between a founder whose insight evaporates between meetings and a founder whose insight accumulates.
What this requires from the founder is the part nobody else has, and it's why I keep saying the AI co-author is the hardest piece to install elsewhere.
The AI is only as useful as the operational context it's loaded with. Sparse prose produces a thin co-author; the AI has nothing to lean on, no conventions to obey, no history to reference. Dense prose produces a thick co-author; the AI starts the session knowing your preferences, your prior decisions, your active blockers, your rules. The leverage of the AI is bounded by the substrate it has to work with. There's no shortcut for this, and the shortcut everyone reaches for, prompting the AI more carefully, doesn't replace having the corpus already written.
A founder who isn't willing to write things down clearly, repeatedly, until the corpus has enough mass to be queryable, can't bootstrap this part of the system. The first month is brutal because there's nothing yet for the AI to load. The second month is easier because the first month's work is now context. By month three the loop is running, and from there it compounds.
The pitch I'd make to another founder isn't "install this and the AI does your work," the pitch is "install this, do the work, and the system will retain it for you," and that's defensible and also the only honest thing to say.
Does this work if I'm not using Claude Code?
Mostly yes, with caveats worth being specific about.
Five of the six pieces of the system, the ones I described in earlier sections, are tool-agnostic. The decision corpus is JSON Lines and markdown; the rule lifecycle is just files; the load-bearing test is a binary classification you can apply by hand; the enforcement substrate is pre-commit hooks and content gates that fire on git commit regardless of which AI tool drafted the change; the meta-mining loop is Python scripts running deterministic queries against the corpus. None of those depend on Claude. They'd work the same if I drafted every word of every decision log myself.
The one piece that's tool-coupled is the AI co-author. And here the honest split is: the substance ports, the implementation details don't.
The substance is a small set of capabilities. An AI agent that, at the start of a session, automatically loads a designated bootloader file and any context files the bootloader points to. A rule layer where rules live in files and get loaded into context based on relevance (either always-loaded or glob-matched against the work in flight). A way to wire shell-level enforcement (pre-commit, pre-push, pre-render) to refuse actions that violate load-bearing rules. A consistent format for the AI to produce decision-log entries that obey the corpus's conventions. None of these are exotic; they're the table stakes most modern AI coding agents have grown into over the past two years.
The implementation details are not portable. The file is named CLAUDE.md because that's what Claude Code reads. The rules live in .claude/rules/ because that's where Claude Code looks for them. The hooks fire on PreToolUse and PostToolUse and SessionStart events because those are Claude Code's hook surfaces. If you're running Cursor, the equivalents are different, .cursor/rules/*.mdc files with their own frontmatter format, custom commands instead of skills, a different event surface for any automation. If you're running Aider, you're configuring .aider.conf.yml and managing context with --read flags. If you're running a tool with a thinner context primitive (ChatGPT's custom instructions field, for example, which is a single text box), the pattern still works but the auto-loading is less seamless and the volume of context you can keep active is lower.
The framework is opinionated about the substrate (decision logs, rule lifecycle, enforcement gates, AI as session-start participant). The framework is not opinionated about which AI tool drives the co-author piece. About eighty percent of an install at another company is tool-agnostic; the other twenty percent is mapping the conceptual pattern onto whatever the company already uses, file naming, rule-loading mechanism, hook syntax, sub-agent equivalents.
This isn't theoretical, but I'm going to tell you when it's tested. As of the date this article is being written, the only production deployment I can speak to is mine, on Claude Code. Other tools' implementations of the substance described above will look different on the inside. The pattern is what travels; the file paths and frontmatter syntax don't. If you're running a tool that doesn't yet have a way to load context at session start automatically, you'll be doing more of that work manually until your tool catches up, and most of them are catching up fast.
6. Meta-mining
The last loop is the one that closes the system on itself.
The corpus is structured enough to query, not just text-searchable but structured, and every record has a date, a session, an author tag, a category tag, a title, and a stable anchor. The cumulative artifact, after a few months of dense use, is large enough that you start finding things in it that you didn't know to look for.
This essay is itself the output of one meta-mining session. About an hour of Friday night. The brief was open: apply the mining metaphor, which the system had separately promoted earlier in the day, to the decision corpus itself, and see what comes up. Six things surfaced.
The first was a lag correlation between two of the most consequential tags. Incidents (something broke) lead rule promotions (something got codified) by about two weeks, at a correlation of plus zero point eight. When the system breaks, the codified response shows up roughly two weeks later, not in the same week. Incidents aren't immediately abstracted into rules. They sit, the consequences play out, the pattern resolves, and only then does the rule get written. That's the load-bearing-rules promotion path made visible as a temporal signal in the corpus.
The second was the substrate-reuse pattern in the load-bearing rule promotions described in section 1. I'd known the rule promotions were happening; I hadn't seen them as an accelerating cadence until I sorted them by date and computed the time-per-enforcement. The data is internal-only, for reasons section 10 unpacks.
The third was a phase-transition day. April thirteenth showed four reversal-class entries (corrections, rollbacks, things-that-were-wrong) clustered with three load-bearing rule promotions, all on the same date. At first glance that looks like a bad day. The actual interpretation is the opposite: that was the day I built the verification infrastructure that made the existing errors publicly nameable. The reversal density wasn't a sign that work-quality dropped; it was a sign that enforcement went up. Errors that had been circulating quietly became writable as [CORRECTION] and [ROLLBACK] tags because there was now a system that caught them. The next two days were the most painful of the project; the load-bearing-rules table dates from that week.
The fourth was the keystone node in the rule graph. I'd built the load-bearing-rules file deliberately as a meta-rule. I hadn't realized, until I rendered the citation graph, that every rule promoted to enforcement runs through it both as a target (older rules cite it) and as a source (it cites every promoted rule in its promotion table). It is structurally the keystone of the rule layer. That node going stale would degrade the whole graph; that node continuing to densify is the visible compounding shape.
The fifth was something I genuinely didn't expect. Five of the twelve commandments have zero explicit citations from any rule file. Commandments six (match the weight of the solution to the weight of the problem), eight (fix at the most general level the evidence supports), nine (be wrong fast), ten (capture what you learn or lose it), and twelve (the work compounds) are all referenced implicitly across the rule layer but never named. The reading I draw from this is mixed. Two of those (six and eight) might be too abstract to wear an enforcement coat; the other three are absolutely load-bearing in spirit and the citation graph is missing them as anchors. There's a sweep of the rule layer waiting to be done that adds explicit commandment cites where the implicit anchoring already exists.
The sixth was an emerging fix class. About five percent of [FIX] titles match keywords for stale-data work: corrected, stale, was-wrong, fabricated, reverted. The actual rate is higher than five percent because keyword search misses prose-only stale fixes. The pattern is consistent and the most recent six weeks of fixes lean heavily on this class: stale entries in open items, stale numbers in slides, stale claims in transcripts, stale unit calculations propagating into derived stats. There's a general principle here, any prose claim against a faster-moving truth needs a freshness check, and it's a candidate for the next load-bearing rule promotion.
Six structural patterns, none of them visible from reading individual decisions in sequence, none discoverable in a Notion doc, none requiring infrastructure I didn't already have. About an hour of compute and a Python script that read the JSON Lines file the corpus rebuilds itself into every time a decision-log file is edited.
The cadence I run meta-mining at is roughly once a month. Friday night session, exploratory brief, low expectations. The output isn't a feature or a fix; it's candidate rules, candidate corrections to the system itself, and surprises worth keeping. Most of the value of any individual session is one or two of those candidates. Over six months, the compound is significant: every meta-mining session produces a small set of structural improvements to the system that runs the company.
This is the loop that closes the corpus on itself, and it's what turns the corpus from a record into something that teaches you back.
7. The portable core
The honest question, after seeing all of the above: how much of this is specific to my company, and how much would survive being installed somewhere else?
I've thought about this carefully because the answer matters. If everything I've described is co-evolved with municipal-records-as-a-business, if the rule lifecycle only works because we have a finite set of CMS vendors and a specific FOAA workflow and a particular shape of buyer, then the system is a curiosity, not an asset. If the bones of it are universal, the system is a thing I could install in your company for an equity stake and it would work.
My read, after spending a month testing the seam between domain-specific and universal: there's an irreducible core of six pieces. Five of them are easy to install. The sixth is the moat.
The right way to think about what this is, before going through the pieces:
It's Rails for a founder-plus-AI company.
Rails was opinionated for web apps. Convention over configuration. It told you where the controller goes, what the model is named, how routing maps to actions, and the cost of fighting those decisions was higher than the cost of accepting them. Rails compounded because the opinions were extracted from running code, not invented from theory. The compounding system is the same shape, applied to a different layer of the stack: an opinionated framework for how a founder-plus-AI operation maintains decisions, rules, and enforcement. The opinions came out of running Municipal Alpha; the framework is what's left when you peel the muni-vertical specifics off the top.
One. A decision corpus with emergent taxonomy.
You start writing decisions down in a structured format with date and session. You don't pre-design the taxonomy; you let it emerge. After a few weeks you'll notice you're tagging things the same way repeatedly. Promote those tags into the schema. The point is that the taxonomy fits the work, because it grew out of doing the work. A pre-designed taxonomy is theater; an emerged one is a map.
This is the cheapest piece to install, a markdown file per day, a naming convention, a ledger that reads the markdown files and produces an index. One afternoon of setup, and from then on it's free.
Two. A rule lifecycle with explicit promotion criteria.
Practice → rule → principle → commandment. A practice is a thing you noticed yourself doing. A rule is a practice with a name and a file. A principle is a rule that subsumes multiple specific rules. A commandment is irreducible.
The promotion criteria matter. A rule should earn promotion to a principle when at least three other rules can be subsumed under it. A principle should earn promotion to a commandment when an independent failure mode demonstrates that violating the principle has consequences the system can't recover from gracefully.
This piece is medium-cost. A handful of files in a rules/ directory. A weekly review that asks "is anything I did this week a candidate for a new rule?" Two hours a week, at most.
Three. The load-bearing test.
For each rule, ask: "If this rule were violated right now, would any tool catch it?" If yes and the tool fails closed, the rule is load-bearing. If yes but only warns, partial. If no, advisory.
Advisory rules decay. The text persists; the force does not. Either wire enforcement or accept that the rule is a reminder, not a rule.
This is the cultural piece, you have to mean it, you have to be willing to look at your favorite "best practices" doc and admit that without enforcement, half of what's written there isn't actually a rule, it's a wish.
Four. An enforcement substrate.
This is where most of the implementation cost lives. You need a way to make rules mechanical. Pre-commit hooks for code rules. Content gates for outbound communication. Schema validators for configuration. Drift detectors for prose-against-data inconsistencies. The exact tools depend on your stack. The pattern is universal: every load-bearing rule lives in code, not text.
A reasonable first version takes one to two weeks of engineering. Subsequent rules plug into the substrate cheaply. This is where the substrate-reuse acceleration described in section 1 comes from.
Five. Meta-mining cadence.
Every thirty days or so, spend a couple of hours running queries against the corpus, not because you need the answer but because the corpus knows things you don't. Lag correlations between tags. Patterns in your fix volume that you didn't notice. Reversal clusters that point to a structural issue. Commandment citations that reveal which abstractions are under-anchored.
The point is to treat the corpus as a teacher, not just a record. Tonight's session, the one that produced this article, found six structural patterns I couldn't have found by reading individual decisions in sequence.
This is essentially free if you have the previous four pieces. It's an evening every month. The output is candidate rules and candidate corrections to the system itself.
Six. The AI co-author with full operational context loaded.
This is the moat.
You can have the previous five pieces and still have a journal. What turns the journal into an operating system is an AI that reads everything, the rules, the recent decisions, the user's preferences and history, the open items, the meta-audits, the retro questions, and applies it to whatever you're working on right now. Session-start loads ~30 KB of operational context. Every action the AI takes is contextualized by that prior state. New decisions enter the corpus in a form that next session's context-loading can use.
This piece is hard to install for two reasons.
First, it requires the founder to write enough prose, with enough density and specificity, that the AI is actually useful. A sparse decision log produces a thin AI co-author. The leverage of the AI is bounded by the substrate it has to work with. There's no shortcut for this. You have to do the work of writing things down clearly, repeatedly, until the corpus has enough mass to be queryable.
Second, the integration has to be wired. The AI has to load the right files at the right moment. The rules have to be in a form the AI can apply. The pre-commit hooks have to know about the AI, and the AI has to know about the pre-commit hooks. None of this is rocket science, but all of it is glue that has to be written and maintained.
A reasonable first version takes a month of dedicated engineering, in a company where the founder is willing to write the prose. In a company where the founder isn't, the install fails. Not because the technique is hard, but because the substrate isn't there for the AI to use.
That's the honest read on portability. Five pieces that are cheap and obvious in hindsight. One piece that's expensive and culturally specific. The compounding system isn't free, but the cost is bounded and the payoff is observable on a chart.
So here's what I'm doing about it.
If you're solo, the first five pieces are open. Genuinely solo, where you're the only person making decisions, writing prose, reviewing rules. If you want the spec, email me at matt@municipalalpha.com with a sentence about what you're building. I'll send back the decision-log schema, rule-lifecycle taxonomy, example rule files, the load-bearing test, the meta-mining script, and a starter CLAUDE.md template. The friction is small and intentional: I want to know who's running this so I can occasionally check back in and learn what surprised them. The whole point of giving the spec away is that the framework gets durable when more than one person is using it.
The boundary that matters isn't the size of the company. It's the 1→2 transition. The moment a second person joins, the system encounters problems the spec doesn't solve. Decision attribution becomes ambiguous. Conventions drift between authors. Two people log the same kind of decision differently and corpus quality degrades. Files get edited from two directions at once. The AI co-author has to know whose session it is and what context they're loading. New joiners can't absorb the corpus the way the founder did, because the founder absorbed it by writing it.
These aren't hard problems for an experienced installer; they're zero problems for a solo operator. That's the line: solo runs free, two-or-more is where I install for an equity stake. The team install isn't "the same thing but bigger," it's a different product solving a different class of problems, and most of the addressable market is past solo.
I think the next iteration of my work is helping other founders compound. The vertical at Municipal Alpha is where the system was proven; making it portable is where it travels. There's an honest qualifier worth being specific about: the multiplayer install isn't a productized service yet. My own company is about to make the 1→2 transition itself, which means the multiplayer install playbook is being written from the inside, in real time, as I work through it for the first time. The framing isn't "I'll install this for you because I've installed it for others." It's "I'll install this for you while I'm building the playbook, and you'll get the playbook as it gets written." The first paid install will look more like a co-development engagement than a productized service. That's the honest version. The price reflects that.
8. The corpus survives team turnover (a hypothesis)
There's an argument I should have made earlier in the article and didn't, because the operational frame I was working in didn't naturally surface it. I want to be honest at the top of this section that the argument I'm about to make is a hypothesis I find compelling, not a validated case. No acquirer has yet bought a company on the strength of its compounding-system substrate. No investor has yet quoted the rule-citation graph as the reason a Series B priced higher. Read the rest of this section as theoretically defensible reasoning that hasn't been tested at exit, not as settled fact.
Most of a company's value lives in people's heads, the decisions you've made, the dead ends you've ruled out, the conventions you've built up about how work gets done, the lessons from incidents nobody wrote down, the reasoning behind why a particular customer is handled a particular way, the institutional memory that lets a senior person say "we don't do it that way, here's why" without having to re-derive the answer. None of that lives in the codebase, none of it lives in the financial statements, it lives in the team, and the team walks.
This is the structural problem at every ownership transition. An acquirer pays for a company and within twelve to twenty-four months loses most of what made the company worth acquiring, because the team is on the earnout cliff and the tacit knowledge leaves with them. A founder raises a Series B and the new investor's diligence reveals that everything actually load-bearing is in the founder's head. A new senior hire takes six months to ramp because the conventions she needs to absorb aren't written down anywhere. A succession planning conversation goes nowhere because the company has no way to transfer judgment, only ownership.
The compounding system addresses this directly, not as a feature but as a structural consequence of how it works.
The decision corpus is the part most people would expect to matter, every decision over the company's life, with reasoning, dated, attributed, traceable. Surface-level tacit knowledge becomes explicit knowledge that can be loaded into anyone's context, including a new hire's, including an acquirer's integration team's. That alone is more transferable institutional memory than most companies have at any size.
The rule lifecycle is the part that actually compounds the value. Rules in this system aren't best practices documents that nobody reads. They're extracted from observed behavior, promoted through specific criteria, enforced mechanically, and cited from each other in a graph. The graph itself is the encoded judgment of the founder and team, not as a single document anyone could write in isolation, but as a structural artifact that emerged from doing the work. An acquirer reading the rules layer is reading "how this company actually operates," not "what someone in marketing wrote about how this company operates."
The enforcement substrate is the part that makes the encoded judgment durable beyond the founder's tenure. Pre-commit hooks don't care who the founder is. Content gates refuse fabricated claims regardless of who pressed send. Schema validators block bad configs whether the original rule-author is at the company or has retired to Maine. The rules survive the people who created them because the rules are wired into the operation, not just into the team's habits.
What this means at the next ownership transition, whichever shape it takes:
- An acquirer gets the company plus the encoded judgment of the team that built it. The earnout cliff matters less because the system retains what the team did, not just the team itself.
- A new investor's diligence finds that the load-bearing knowledge isn't in any single person's head. The single-point-of-failure risk on the founder is meaningfully lower.
- A senior hire ramps faster because the conventions she needs to absorb are loaded into her AI co-author's context the moment she starts working in the relevant area. The corpus does the onboarding the founder otherwise would have done in person.
- A succession conversation has somewhere to point. "The system retains how we operate; the next operator inherits the substrate, not just the title."
This is the part of the framework I expect, but cannot yet prove, would interest investors most, because it speaks to the structural question they actually care about: what makes this company harder to lose value from, not just easier to operate today. The reasoning above is what I find compelling about why the substrate would survive transitions, encoded judgment that doesn't depend on retention, rules wired into the operation rather than into habits, conventions that load into a new joiner's context the moment they start working in the relevant area. The proof would be an actual acquirer or investor weighing it, and that hasn't happened yet.
The meta-business pitch I'm building around this, install the system at your company for an equity stake, is partly an operational argument (you'll compound faster) and partly an enterprise-value argument (your encoded decisions become a transferable asset). Founders who think only about today's velocity will install for the operational argument. Founders who are starting to think about exit, succession, or institutional capital will install for the enterprise-value argument. Both arguments are honest. They're describing the same artifact from different angles.
9. What it doesn't do
I want to be specific about the limits, because if this article does its job some people will install the system and find that it doesn't do what they hoped. The limits are not hidden footnotes; they're the load-bearing parts of choosing whether the system is for you.
It doesn't replace founder judgment. The AI co-author applies rules that were extracted from earlier judgments. It does not invent new rules, and it does not make the abstraction call when something it's seen four times now is finally worth promoting from practice to rule. That call still belongs to me. The system retains my judgment; it doesn't manufacture new judgment.
It doesn't work for founders who won't externalize their thinking. This is the most important limit and the one I want to be sharpest about.
The system is a garbage-in-garbage-out amplifier.
Sparse input produces a sparse corpus, which produces a thin AI co-author, which produces decisions that don't get retained, which produces nothing for the next session to inherit, which produces no compounding, which produces no chart. The chain breaks at the first link. If the founder isn't willing to write down their reasoning in real time, what they decided, why they decided it, what they ruled out, what they're worried about, what surprised them, what they noticed about how the work went today, the substrate that everything else depends on never gets built.
This is not a skill issue. Plenty of capable founders simply don't externalize. They make the call, the call works, they move on. The thinking happens in their head and stays there. For some founders this is the right operating mode and the system would be friction without payoff. For others it's the failure mode they keep blaming on the wrong thing, they wonder why their company isn't compounding, why every senior hire takes six months to ramp, why they keep redoing decisions they're sure they made before, why nothing they learn last quarter shows up in how they operate this quarter. The cause is the same in every case: the thinking never left their head.
Installing this system at a company whose founder won't externalize is a waste of both parties' time, the substrate doesn't grow, the rules don't get extracted because there's nothing to extract from, the AI co-author has empty context to load, and the compounding chart doesn't materialize because there's nothing to compound. The honest read on whether this is for you starts with: am I willing to write things down, every day, even when it feels like overhead, even when I'd rather just keep moving. If the answer is no, save your equity stake, nothing about this system will work for you.
The corollary, which is also worth being honest about: an investor or acquirer reading the corpus is reading exactly what you put in. The system is transparent. If your reasoning is sharp, it will read as sharp; if your reasoning is muddled, it will read as muddled. For most founders that's a feature, the encoded judgment is durable, the company is more transferable. For founders whose advantage is partly the inscrutability of how they make decisions, the transparency is itself a deterrent. Both reactions are legitimate. The system rewards the first kind of founder and punishes the second.
It doesn't make the work easier. It makes the work retain. The actual decisions, the actual judgment, the actual founder-effort to figure out the right thing to do, all of that is unchanged. What changes is that you don't redo it next session. You don't have to remember the rule you set last month, because the rule is loaded automatically. You don't have to re-derive the conclusion you reached last week, because the conclusion is in the corpus. The system is leverage on cumulative effort, not a substitute for current effort.
It doesn't prevent rat-holes; it makes them visible. The system has a rat-hole guard that runs at session start, it asks whether the work I'm about to do produces analyzable, publishable signals this week, and if not it flags the work as a candidate rat-hole. The flag isn't a veto, I can still choose to spend the session on the rat-hole, the system just makes the choice conscious instead of making it for me.
It doesn't replace good taste. You still have to know which decisions matter enough to log, which rules are worth promoting, which commandments are load-bearing and which are theater. Bad taste produces a corpus full of trivia, a rules directory full of wishlist items, and a commandments file that nobody respects. The system amplifies the taste you bring to it, in either direction.
It is not a productivity hack. If you're optimizing for "shipping more features per week," the system feels like overhead. The session-start protocol takes time. The decision-log writing takes time. The rule-lifecycle thinking takes time. The meta-mining takes time. None of those activities ship a feature. What they do is raise the baseline that next month's work starts from. If you're optimizing for "this company is harder to compete with every month I run it" rather than for short-term throughput, the system pays for itself; if you're not, it doesn't.
The right reader for this article isn't a founder looking for life-hacks. It's a founder who's noticed that their company stops compounding when they get tired, who's tired of redoing decisions they're sure they made before, who's run out of patience for advice that lives in a Notion page nobody reads, who's willing to invest in infrastructure that compounds whether they're tired or not, and who's willing to externalize their thinking in writing, every day, as the price of admission.
If that's not you, the article was probably interesting and not actionable, and I'd rather you knew that now than after you tried to install something that doesn't fit.
10. The honest case against
Section 9 is about who the system isn't for. Section 10 is about where the article itself shouldn't be trusted. Both are limits worth being explicit about; the second class is harder to surface and probably more important. The system this article describes is built on the principle that being wrong fast is more valuable than being right slowly, so the case against the article belongs inside the article rather than in the comment thread.
A prior draft of this essay led with a chart of the load-bearing rule promotion cadence. I removed it. The chart was the framing's centerpiece, seven promotions over a month, with the gaps between them shortening from sixteen days to five to two to two. The pattern is consistent with substrate reuse making each subsequent enforcement cheaper to wire. It's also consistent with a learning curve on a tightening toolchain, with low-hanging fruit getting picked first, or with a productive stretch that hasn't ended yet. The chart didn't tell you which. The deeper problem is that once a metric like that is published, every future cadence is dual-purpose, operational and reputational, with the reputational pull warping the operational reading. That's a specific Goodhart failure mode and the chart was the system's sharpest exposure to it. The cadence data stays internal as diagnostic evidence, I'm not committing to maintaining the trajectory as a public claim. The phenomenon I'm describing (substrate reuse making the next enforcement cheaper than the last) is still observable and still falsifiable internally if it stops being true.
"Compounding" overclaims as a single word. Section 4 distinguishes substrate reuse, corpus accumulation, and rule-citation densification, three different dynamics with different return curves. Lumping them under one term makes the system sound more unified than it is. The cadence-acceleration is a learning curve, the corpus accumulation is linear, and only the rule-graph densification has the network-effect property that "compounding" usually implies in its strongest sense, and the article's three-week chart of that graph isn't long enough to say much. The honest framing across the three is something like "structurally reinforcing dynamics that, taken together, plausibly produce compounding returns over enough time," which is less punchy and more accurate.
The enterprise-value argument is theoretical, not validated. Section 8 makes the case as a hypothesis I find compelling. No acquirer has bought a company on the strength of its compounding-system substrate, no investor has priced a round on the rule-citation graph. The reasoning is internally coherent, the validation is missing, and the article should not be read as if the validation has happened.
The multiplayer install is a product that doesn't exist yet. My own company hasn't completed the 1→2 transition. Selling a "team install for equity" service when I haven't installed the team version anywhere, including here, is selling a product that's being designed in real time. The honest version of the offer is "co-development engagement, the playbook gets written as I install it for the first time, you get the playbook as it gets written." That's a real offer at a real price, but it isn't productized service-delivery and shouldn't be priced as such.
Measurement artifacts are a category of risk worth naming. The matt:claude authorship metric turned out to be a session-naming convention shift, not an altitude shift; this is admitted in section 5 but the implication is broader. The volume curve in chart 1 reflects when tagging discipline started, not when work changed. The citation graph reflects only inbound markdown-references, not other forms of dependency. The meta-mining session that produced the article is itself an instance of the system, which means the article's evidence base is partly produced by the system the article describes. Several of the cited numbers are robust to convention shifts (the load-bearing-rules table is a hand-maintained artifact; the cadence gaps come from explicit dates); several others aren't. Treat the metrics with a grain of salt accordingly. The system's own meta-mining is the right tool for catching this class of artifact, and finding it caught the convention-shift one is some evidence the loop works. Finding it caught one is not evidence it caught all.
Self-selection plausibly explains a meaningful fraction of the system's apparent value. Section 9 admits the system requires founders willing to externalize their thinking daily. The honest extension of that admission: founders with that habit tend to compound anyway, and the marginal contribution of the elaborate substrate over a simpler version (a structured journal, pre-commit hooks, an AI assistant with a system prompt) is genuinely hard to isolate from the personality trait that made the founder build the elaborate version in the first place. The article cannot rule out that what it's describing is mostly an instrumented account of how a particular kind of founder operates, with the system providing leverage at the margin rather than producing the underlying compounding. I think the marginal contribution is real and meaningful; the article cannot prove it.
The simpler alternative is probably 80% as good for early-stage founders. A founder running a structured markdown journal, pre-commit hooks for code rules, and an AI assistant with a thoughtful system prompt would capture most of the operational benefit at maybe 20% of the complexity. The four-stage rule lifecycle, the load-bearing-rules promotion table, the meta-mining cadence, the rule-citation graph, these are load-bearing for the framework (the artifact you'd install at someone else's company, the thing that needs articulated structure to be teachable) and load-bearing for the altitude at which the system is meant to operate (a meta-business that installs at multiple companies). For an early-stage solo founder, they're probably overhead. The article's bias is toward the elaborate version because the elaborate version is what the meta-business pitch needs to exist. A reader who installs only the simpler subset and gets most of the operational benefit has not failed; they have correctly identified that they don't need the framework altitude yet.
The 80% claim is bounded to the solo altitude, and that boundary matters for the pricing logic. At multiplayer, the simpler version doesn't address the wiring problems a multi-person install runs into, convention drift between authors, decision attribution, conflict resolution on shared files, context-routing per person, onboarding friction. The elaborate version is what addresses those problems, not what amplifies the operational benefit. So the equity engagement and the 80% concession aren't competing offers on the same product; they target different stages. Solo: the simple version is probably enough, install it yourself. Past solo: the elaborate version is what addresses problems the simple version doesn't see, and the install work is what the equity stake pays for.
The system can compound bad judgment as efficiently as it compounds good. The rule lifecycle (practice → rule → principle → commandment) is entirely dependent on the founder's taste and interpretation. If the founder extracts the wrong lesson from an incident, the system codifies that lesson, enforces it mechanically, and builds future rules on top of it. A flawed principle can become a load-bearing rule and the system will treat it as gospel. The single point of failure is the founder's judgment, and if it degrades silently, the system accelerates the company's decline along with everything else. A periodic review-and-cull process is the structural response to this, and after the article's first draft I shipped one, a quarterly cull rule that forces four questions per quarter on each rule, has it fired in ninety days, has it fired constantly without producing the outcome it was promoted for, do its triggering conditions still hold, is the cull itself producing more value than its friction. Whether the cull survives contact with a real cull session I can't yet say, the first one runs in Q3 2026, and the load-bearing test is whether anything actually gets retired or modified, or whether it becomes ceremony.
The AI substrate is rented infrastructure with a half-life I don't control. The framework is in principle tool-agnostic, but the current implementation is wired to one vendor's model and one vendor's coding agent and that wiring is closer to load-bearing than the framing admits. Three specific exposures. Model deprecation forces re-tuning, every rule the corpus implicitly assumes about how the current model interprets ambiguity becomes a maintenance event when the model changes. Context windows scale up the way prices come down, but lost-in-the-middle and instruction-following degradation at the deep end of a window aren't priced in by capacity claims, and a five-hundred-day corpus loaded against an indifferent reader retrieves less of itself than a fifty-day corpus loaded against an attentive one. Tool-layer convention drift is the slowest of the three and the one that breaks enforcement most quietly, the agent's behavior inside a pre-commit hook is what's actually rented and that's harder to detect when it shifts. The principled response is the one the portability section already names, design the substrate so the AI is replaceable. The current system passes that test on paper, I haven't done the swap.
The 1→2 multiplayer transition is a present-tense design gap, not just a future build problem. The article frames the multiplayer install as the next product to build, but it's also a present design gap in the existing solo system. What happens when two people disagree on the interpretation of an event for the decision log? Who arbitrates a conflict over promoting a rule? The current system assumes a single, authoritative perspective and breaks at the first significant disagreement. The honest extension is that the multiplayer install isn't just adding new mechanics, it's adding mechanics for things the solo system never had to solve. Anyone installing this past one person should expect those mechanics to be designed in real time, not pulled from a productized playbook.
There's no overhead detector. The system requires daily discipline to externalize thinking, define rules, run meta-mining. Under pressure, a founder might cut corners on log entries, skip the rule lifecycle review, defer meta-mining indefinitely, and never notice the corpus quality has degraded enough to break the AI co-author's leverage. There's no health check that flags when corpus density or rule promotion cadence falls below a useful threshold. The system should detect this and force a conscious decision: either recommit to the discipline, or formally deprecate the parts that aren't paying for themselves anymore. Until that detector exists, the system's overhead can quietly outgrow its value without anyone noticing in time.
The article's strongest move is the substrate-reuse claim in section 1, the one I kept internal rather than displayed, because keeping the cadence falsifiable mattered more than putting it on the page. Its weakest is treating either of the two charts I do show as proof of a general claim they can only be evidence for. The case against the article is mostly the gap between the confidence of the framing and the thinness of the evidence; the case for the article is that it's still the most concrete attempt I've seen at making compounding-claims falsifiable rather than rhetorical. Both can be true. Section 10 exists so a reader doesn't have to choose between them silently.
The single thing that would resolve the most of these concessions at once is the second installation. As long as this article is one founder reporting on his own system, it's an instrumented case study no matter how carefully it's written. The version of this article that closes the gap, that turns "interesting case study" into "installable framework", is the one written after someone else has run the system at their own company and reported back. That's the load-bearing next move; it's the test the article cannot itself perform; and it's the specific thing the next several months of this work need to produce.
A note in closing
Two things to say before this ends.
The first is about the current state of the work, for anyone who wants to act on it. Municipal Alpha, the company this system runs, is in flight. The case study is real and live; the data product is shipping to investors and operators in capital markets and infrastructure. The system underneath is being extracted into a portable form because that's the next iteration: install the system at other companies for an equity stake, with the spec available to solo founders on request and the team install priced as an equity engagement for anything past one person. If you want the spec, email me at matt@municipalalpha.com with a sentence about what you're building. I'll send it.
There's a useful self-test for whether this is for you. If you're solo and you've been reading this thinking "I should be doing this," send me an email, get the spec, install it, and tell me what surprised you. That's the whole ask. If you're past solo and the parts about multiplayer wiring landed harder than anything else in the article, the right next step is a thirty-minute call. Bring the symptom you're trying to solve; I'll bring the playbook. The team install is where I take an equity stake.
The second thing, briefly, is a callback to the disclosure at the top: the prose you've just read was the AI co-author working with the conventions and rules established across the corpus this article describes. That's not incidental to the argument; it's an example of it. The system retains what I do and compounds on it; the article you're closing is one of the things it retained.
The work compounds. That's the whole argument. The rest is implementation detail.